在网络编程的世界里,性能是开发者永恒的追求。在通往高性能网络应用的道路上,有一块巨大而常见的“绊脚石”——同步阻塞网络I/O。它以其直观简单的模型,吸引着无数初学者,却也因其固有的缺陷,成为系统吞吐量和并发能力提升的主要瓶颈。本文将通过图解的方式,深入剖析同步阻塞网络I/O的工作原理、性能瓶颈及其在高并发场景下的困境。
一、 什么是同步阻塞网络I/O?
同步阻塞I/O是最经典、最直观的网络编程模型。其核心特点是:进程(或线程)在进行I/O操作(如read, accept, connect)时,必须等待该操作彻底完成(数据就绪且从内核空间拷贝到用户空间)后才能继续执行后续代码。在此期间,调用者会被操作系统挂起,进入“阻塞”状态,无法执行任何其他任务。
我们可以用一个简单的“服务员-顾客”餐厅模型来比喻:
- 同步:服务员(应用程序线程)必须亲自完成从点单(发起请求)到上菜(获得数据)的整个流程,不能中途离开去服务其他桌。
- 阻塞:如果厨房(内核/网络)做菜很慢,服务员就必须在出菜口一直站着等,直到菜做好端走。这段时间他什么都干不了。
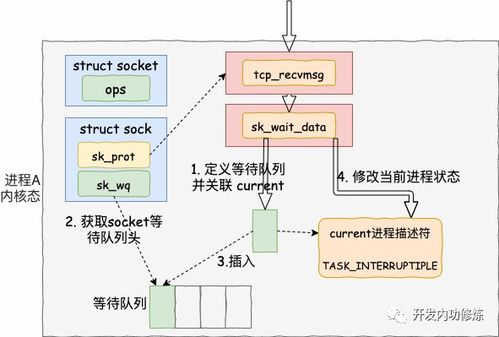
二、 工作原理图解:以Socket read()为例
让我们跟随一次典型的Socket读取操作,看看线程是如何被“卡住”的。
[用户空间] [内核空间] [网络/磁盘]
| | |
| 调用 read(socket) | |
|------------------>| |
| | 数据未就绪,线程阻塞 |
| 线程被挂起 |<---等待数据包------|
| (阻塞中) | |
| | 数据到达,拷贝至内核缓冲区 |
| |<===================|
| | 数据从内核缓冲区拷贝到用户缓冲区 |
| 线程被唤醒 |------------------>|
|<------------------| |
| read()返回,继续执行 | |关键的两阶段等待:
1. 等待数据就绪:数据包还在网络上“飞”,或者对端还未发送。此时,内核让线程休眠,直到数据到达网卡并被拷贝到内核的接收缓冲区。
2. 等待数据拷贝:数据到达内核缓冲区后,内核需要将其从内核空间拷贝到用户空间(即read函数指定的应用层缓冲区)。完成拷贝后,read调用才返回成功。
在整个过程中,调用线程在“等待就绪”和“等待拷贝”这两个阶段都是完全停滞的。
三、 为何成为高性能的“绊脚石”?
同步阻塞模型的简单性是以牺牲资源利用率和并发能力为代价的。
1. 线程资源浪费严重(图解:线程池的窘境)
在高并发服务器中,通常采用“一个连接一个线程”的模式。
[客户端1] ---> [线程1:阻塞在read()上]
[客户端2] ---> [线程2:阻塞在accept()上]
[客户端3] ---> [线程3:阻塞在read()上]
[客户端4] ---> [线程4:正在处理...]
[客户端...] [线程N:大部分时间在沉睡]
\ /
[线程池]- 问题:每个连接都需要一个独立的线程服务。而线程是操作系统宝贵的资源,创建、销毁、调度都有开销。成千上万的连接意味着成千上万的线程,上下文切换将消耗大量CPU时间。
- 更糟的是:这些线程中的绝大部分时间都花在
read、write的等待上(即上图的“阻塞中”状态),CPU处于闲置状态。资源(线程内存、调度开销)被大量占用,却未产生实际计算价值。
2. 并发能力受限于线程数
系统的最大并发连接数理论上等于线程池的最大线程数。而一个进程能创建的线程数是有限的(受限于内存、内核参数等)。通常,当并发连接数超过数千时,这种模型就会变得极其低效甚至崩溃。
3. 慢客户端导致的级联阻塞
如果一个客户端网络很慢,读取它发送的一个数据包需要5秒,那么服务它的线程就会被堵住5秒。这期间,该线程无法处理其他任何请求。如果这样的慢客户端多了,线程池中的线程会迅速被“冻住”,即使服务器CPU空闲,也无法响应新来的快速客户端,导致服务整体瘫痪。
四、 与高性能模型的对比
理解阻塞之痛,才能明白非阻塞I/O、I/O多路复用(如select/poll/epoll)、异步I/O等高性能模型的价值。它们的核心思路是一致的:让一个线程能够管理多个连接,只在连接真正有I/O事件可处理(数据可读、可写)时,才进行实际操作,避免无谓的等待。
以Linux的epoll为例的对比示意图:
`
同步阻塞模型 (1:1)
线程A ---> 连接1 (阻塞)
线程B ---> 连接2 (阻塞)
线程C ---> 连接3 (阻塞)
... 一万个连接需要一万个线程。
I/O多路复用模型 (1:N)
|--- 连接1 (有数据,处理)
线程A ---> |--- 连接2 (无事件,跳过)
| |--- 连接3 (有数据,处理)
(epoll) |--- ... 一万个连接
|--- 连接10000 (无事件,跳过)`
一个工作线程通过epoll<em>wait可以同时监听上万个连接。当其中某些连接有事件发生时,epoll</em>wait返回,线程只去处理这些“活跃”的连接,处理完继续监听。线程资源被高效复用。
五、 与启示
同步阻塞网络I/O是学习网络编程的重要起点,它清晰地揭示了I/O操作的本质。但在生产环境,尤其是需要高并发、高性能的服务器场景(如Web服务器、游戏网关、即时通讯服务等)中,它已成为必须跨越的“绊脚石”。
- 适用场景:客户端程序、并发要求极低(如内部管理工具)、或追求极致简单性的场景。
- 规避策略:迈向高性能,必须掌握非阻塞I/O与I/O多路复用技术(
select/poll/epoll/kqueue),或直接使用基于这些机制的高级框架(如Netty、libevent)。对于磁盘I/O,则可考虑使用异步I/O(AIO)。
理解这块“绊脚石”,不仅是为了避开它,更是为了深刻理解操作系统如何进行I/O调度、应用程序如何与内核协作,从而为构建真正高性能、高可用的网络服务打下坚实基础。